DiT-Block Policy
The Ingredients for Robotic Diffusion Transformers
Our method allows for stable training of high-capacity Diffusion Transformer Policies.
Overview
This paper identifies, studies, and improves key architectural design decisions for high-capacity diffusion transformer policies. Our model, named DiT-Block Policy, makes a few simple, yet impactful, changes to the vanilla diffusion transformer recipe. Namely, we add adaLN-zero layers to the transformer blocks and further optimize the input encoding layers. The resulting architecture significantly outperforms the state of the art in solving long-horizon (1500+ time-steps) dexterous tasks on a bi-manual ALOHA robot, without the excruciating pain of per-setup hyper-parameter tuning. Finally, we find that our policies show improved scaling performance when trained on 10 hours of highly multi-modal, language annotated ALOHA demonstration data, which we've open-sourced for the community's benefit.
Approach
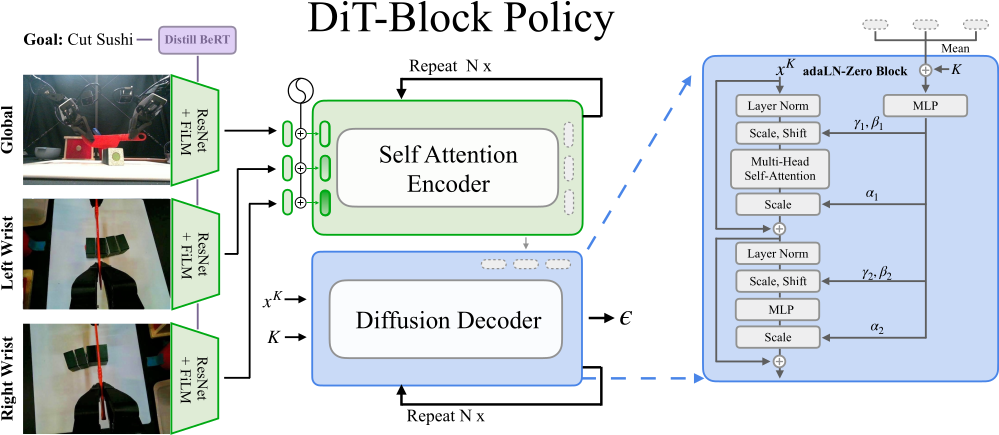
DiT-Block Policy Architecture.
Our method -- DiT-Block Policy -- is a Transformer neural network architecture designed specifically to be a highly performant conditional noise network for robotic diffusion policies. The DiT-Block Policy architecture is visualized above. First, the text goal and robot proprioception inputs are encoded into observation vectors. Similarly, the time-step (k) is turned into an embedding vector using sinusoidal Fourier Features and a small MLP network. Then, all these embedding vectors are combined with the input noise vector using an encoder-decoder Transformer architecture to produce the denoising output. We make two simple, yet critical, additions that significantly boost performance: (1) we replace standard cross-attention layers with adaLN-zero layers in the transformer decoder; and (2) we parameterize the image encoders with separate ResNet-18 networks per camera input. Both of these changes significantly boost training stability and final performance.
BiPlay Dataset

BiPlay Dataset
Inspired by prior work on data scaling[1,2,3], we seek to understand how Dit-Block Policies will behave as they are trained on increasingly diverse demonstrations data. However, the few (open-source) bi-manual datasets that do exist[4,5], only consist of a handful of tasks, collected using the same controlled scenes/objects. As a result, they are not useful for testing generalization in our bi-manual setting. To address this shortcoming, we collected and annotated BiPlay, a more diverse bi-manual manipulation dataset with randomized objects and background settings. We collected BiPlay as a series of 3.5 minute long episodes. For each episode, we constructed a random scene with various objects, and solved a sequence of tasks within that scene. After collection, the episodes were broken into clips that were in turn annotated with appropriate language task descriptions. The final dataset contains 7023 clips spanning 10 Hrs of robot data collection.
Results

BibTeX
@article{dasari2024ditpi,
title={The Ingredients for Robotic Diffusion Transformers},
author = {Sudeep Dasari and Oier Mees and Sebastian Zhao and Mohan Kumar Srirama and Sergey Levine},
journal = {arXiv preprint arXiv:2410.10088},
year={2024},
}